Apply DA Tag

Data can be a powerful tool. But the key to data isn’t just accessing it. It’s interpreting it — and using it to make better decisions that benefit your business and your customers. Here are four key areas where business leaders can use data in more meaningful ways to impact decisions: Grow your business — Reveal patterns, trends and associations to better evaluate business opportunities and respond to market fluctuations. Improve efficiency — Optimize operations and improve use of time to acquire more customers for less. Manage fraud and credit risk — The better you know your customers, the less risk you’ll have. Validate manually entered information — Determine the best actions to deliver the most effective outcomes for both existing and future customers. According to Forbes, by the year 2020 about 1.7 megabytes of new information will be created every second for every human being.1 Get the most out of our data-driven economy to remain competitive. Learn more> 1Bernard Marr, “Your enterprise competes to win. Does your digital infrastructure?,” Forbes, September 2015.

Although it’s hard to imagine, some synthetic identities are being used for purposes other than fraud. Here are 3 types of common synthetic identities and why they’re created: Bad — To circumvent lag times and delays in establishing a legitimate identity and data footprint. Worse — To “repair” credit, hoping to start again with a higher credit rating under a new, assumed identity. Worst — To commit fraud by opening various accounts with no intention of paying those debts or service fees. While all these synthetic identity types are detrimental to the ecosystem shared by consumers, institutions and service providers, they should be separated by type — guiding appropriate treatment. Learn more in our new white paper produced with Whitepages Pro, Fighting synthetic identity theft: getting beyond Social Security numbers. Download now>

An introduction to the different types of validation samples Model validation is an essential step in evaluating and verifying a model’s performance during development before finalizing the design and proceeding with implementation. More specifically, during a predictive model’s development, the objective of a model validation is to measure the model’s accuracy in predicting the expected outcome. For a credit risk model, this may be predicting the likelihood of good or bad payment behavior, depending on the predefined outcome. Two general types of data samples can be used to complete a model validation. The first is known as the in-time, or holdout, validation sample and the second is known as the out-of-time validation sample. So, what’s the difference between an in-time and an out-of-time validation sample? An in-time validation sample sets aside part of the total sample made available for the model development. Random partitioning of the total sample is completed upfront, generally separating the data into a portion used for development and the remaining portion used for validation. For instance, the data may be randomly split, with 70 percent used for development and the other 30 percent used for validation. Other common data subset schemes include an 80/20, a 60/40 or even a 50/50 partitioning of the data, depending on the quantity of records available within each segment of your performance definition. Before selecting a data subset scheme to be used for model development, you should evaluate the number of records available in your target performance group, such as number of bad accounts. If you have too few records in your target performance group, a 50/50 split can leave you with insufficient performance data for use during model development. A separate blog post will present a few common options for creating alternative validation samples through a technique known as resampling. Once the data has been partitioned, the model is created using the development sample. The model is then applied to the holdout validation sample to determine the model’s predictive accuracy on data that wasn’t used to develop the model. The model’s predictive strength and accuracy can be measured in various ways by comparing the known and predefined performance outcome to the model’s predicted performance outcome. The out-of-time validation sample contains data from an entirely different time period or customer campaign than what was used for model development. Validating model performance on a different time period is beneficial to further evaluate the model’s robustness. Selecting a data sample from a more recent time period having a fully mature set of performance data allows the modeler to evaluate model performance on a data set that may more closely align with the current environment in which the model will be used. In this case, a more recent time period can be used to establish expectations and set baseline parameters for model performance, such as population stability indices and performance monitoring. Learn more about how Experian Decision Analytics can help you with your custom model development needs.

The business case for identity verification and risk assessment tools is most compelling when it includes a broad range of both direct and indirect factors. Here are 3 indirect measures we suggest you consider: Customer experience improvement — With 72% of businesses focused on service, according to Forrester Research,* the value of reduced friction can’t be overstated Reputation and brand protection — The monetary cost of fraud losses can be high, but the impact on customer relationships and brand integrity can be even higher. Compliance — Noncompliance costs an average of 2.65 times more than investing in a technology-based compliance solution. Justifying investment in fraud prevention technology can be challenging. A business case built on the right data can pave the way to upgrading your identity verification and risk assessment technology. Learn more in our buyer's guide>

Data is a part of a lot of conversations in both my professional and personal life. Everything around us is creating data – whether it’s usable or not is a business case for opportunity. Think about how many times a day you access the television, your phone, iPad or computer. Have a smart fridge? More data. Drive a car? More data. It’s all around us and can help us make more informed decisions. What is exciting to me are the new techniques and technologies, like machine learning, artificial intelligence and SaaS-based applications, that are becoming more accessible to lenders for use in managing their relationships with customers. This means lenders – whether a multi-national bank, online lender, regional bank or credit union – can make better use of the data they have about their customers. Let’s look at two groups – Gen-X and Millennials – who tend to be more transient than past generations. They rent not buy. They are brand loyal but will flip quickly if the experience or their expectations aren’t met. They live out their lives on social media yet know the value of their information. We’re just now starting to get to know the next generation, Gen Z. Can you imagine making individual customer decisions at a large scale on a population with so many characteristics to consider? With machine learning and new technologies available, alternative data – such as social media, visual and video data – can become an important input to knowing when, where and what financial product you offer. And make the offer quickly! This is a stark change from the days when decisions were based on binary inputs, or rather, simple yes/no answers. And it took 1-3 days (or sometimes weeks) to make an offer. More and more consumers are considering nontraditional banks because they offer the personalization and speed at which consumers have become accustomed. We can thank the Amazons of the world for setting the bar high. The reality is - lenders must evolve their systems and processes to better utilize big data and the insights that machine learning and artificial intelligence can offer at the speed of cloud-based applications. Digitization threatens to lower profits in the finance industry unless traditional banks undertake innovation initiatives centered on better servicing the customer. In plain speak – banks need to innovate like a FinTech – simplify the products and create superior customer experiences. Machine learning and artificial intelligence can be a way to use data for making more informed decisions faster that deliver better experiences and distinguish your business from the next. Prior to Experian, I spent some time at a start-up before it was acquired by one of the large multi-national payment processors. Energizing is a word that comes to mind when I think back to those days. And it’s a feeling I have today at Experian. We’re taking innovation to heart – investing a lot in revolutionary technology and visionary people. The energy is buzzing and it’s an exciting place to be. As a former customer of 20 years turned employee, I’ve started to think Experian will transform the way we think about cool tech companies!

The economy remains steady, maintaining a positive outlook even though the GDP growth slowed in the first quarter. Real estate is holding ground even as rates rise. We’ve reached a 7-year high in 30-year fixed-rate mortgages, which could have a longer-term effect on this market. Bankcard may be reaching its limit — outstanding balances hit $764 billion and delinquency rates continue to rise. While auto originations were flat in Q1, performance is improving as focus moves away from subprime lending. The economy remains steady as we transition from 2017. Keep an eye on inflation and interest rates in regard to their possible short-term economic impact. Learn more about these and other economic trends with the on-demand recording of the webinar. Watch now

According to our recent research for the State of Alternative Credit Data, more lenders are using alternative credit data to determine if a consumer is a good or bad credit risk. In fact, when it comes to making decisions: More than 50% of lenders verify income, employment and assets as well as check public records before making a credit decision. 78% of lenders believe factoring in alternative data allows them to extend credit to consumers who otherwise would be declined. 70% of consumers are willing to provide additional financial information to a lender if it increases their chance for approval or improves their interest rate. The alternative financial services space continues to grow with products like payday loans, rent-to-own products, short-term loans and more. By including alternative financial data, all types of lenders can explore both universe expansion and risk mitigation. State of Alternative Credit Data

In my first blog post on the topic of customer segmentation, I shared with readers that segmentation is the process of dividing customers or prospects into groupings based on similar behaviors. The more similar or homogeneous the customer grouping, the less variation across the customer segments are included in each segment’s custom model development. A thoughtful segmentation analysis contains two phases: generation of potential segments, and the evaluation of those segments. Although several potential segments may be identified, not all segments will necessarily require a separate scorecard. Separate scorecards should be built only if there is real benefit to be gained through the use of multiple scorecards applied to partitioned portions of the population. The meaningful evaluation of the potential segments is therefore an essential step. There are many ways to evaluate the performance of a multiple-scorecard scheme compared with a single-scorecard scheme. Regardless of the method used, separate scorecards are only justified if a segment-based scorecard significantly outperforms a scorecard based on a broader population. To do this, Experian® builds a scorecard for each potential segment and evaluates the performance improvement compared with the broader population scorecard. This step is then repeated for each potential segmentation scheme. Once potential customer segments have been evaluated and the segmentation scheme finalized, the next step is to begin the model development. Learn more about how Experian Decision Analytics can help you with your segmentation or custom model development needs.

Marketers are keenly aware of how important it is to “Know thy customer.” Yet customer knowledge isn’t restricted to the marketing-savvy. It’s also essential to credit risk managers and model developers. Identifying and separating customers into distinct groups based on various types of behavior is foundational to building effective custom models. This integral part of custom model development is known as segmentation analysis. Segmentation is the process of dividing customers or prospects into groupings based on similar behaviors such as length of time as a customer or payment patterns like credit card revolvers versus transactors. The more similar or homogeneous the customer grouping, the less variation across the customer segments are included in each segment’s custom model development. So how many scorecards are needed to aptly score and mitigate credit risk? There are several general principles we’ve learned over the course of developing hundreds of models that help determine whether multiple scorecards are warranted and, if so, how many. A robust segmentation analysis contains two components. The first is the generation of potential segments, and the second is the evaluation of such segments. Here I’ll discuss the generation of potential segments within a segmentation scheme. A second blog post will continue with a discussion on evaluation of such segments. When generating a customer segmentation scheme, several approaches are worth considering: heuristic, empirical and combined. A heuristic approach considers business learnings obtained through trial and error or experimental design. Portfolio managers will have insight on how segments of their portfolio behave differently that can and often should be included within a segmentation analysis. An empirical approach is data-driven and involves the use of quantitative techniques to evaluate potential customer segmentation splits. During this approach, statistical analysis is performed to identify forms of behavior across the customer population. Different interactive behavior for different segments of the overall population will correspond to different predictive patterns for these predictor variables, signifying that separate segment scorecards will be beneficial. Finally, a combination of heuristic and empirical approaches considers both the business needs and data-driven results. Once the set of potential customer segments has been identified, the next step in a segmentation analysis is the evaluation of those segments. Stay tuned as we look further into this topic. Learn more about how Experian Decision Analytics can help you with your segmentation or custom model development needs.

On May 11, 2018, financial institutions will be required to perform Customer Due Diligence routines for their legal entity customers, such as a corporation or limited liability company. Here are 3 facts that you should know about this upcoming rule: When validating ownership, financial institutions can accept what customers have provided unless they have a reason to believe otherwise. Some possible trigger events requiring review of beneficial ownership information for existing accounts include: change in ownership and law enforcement warrants or subpoenas. When collecting and updating beneficial ownership information, the financial institution must retain the original and updated information. While financial institutions are required to collect the same basic customer identification program information from business owners that is required from consumer customers, your current policies may not satisfy this new rule. Learn more
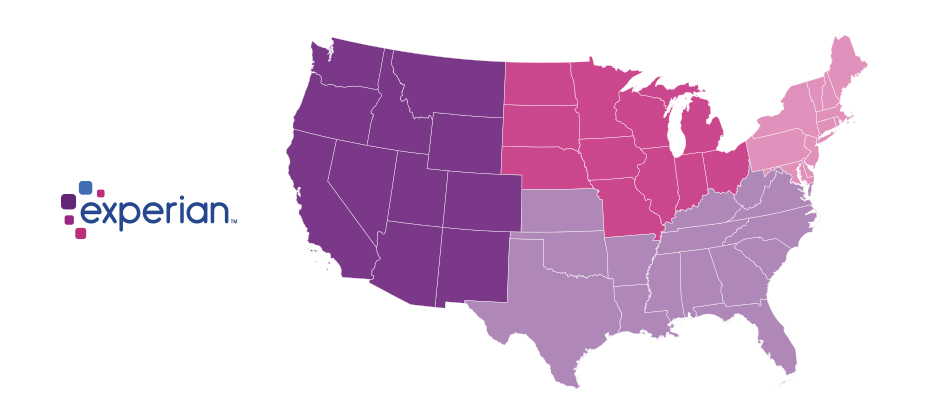
With 16.7 million reported victims of identity fraud in 2017 (that’s 6.64 percent of the U.S. population), it was another record year for the number of fraud victims. And as online and mobile transaction growth continued to significantly outpace brick-and-mortar growth, criminal attacks also grew rapidly. This past year, we saw an increase of more than 30 percent in e-commerce fraud attacks compared with 2016. As we’ve done over the past three years, Experian® analyzed millions of online transactions to identify fraud attack rates for both shipping and billing locations across the United States. We looked at several data points, including geography and IP address, to help businesses better understand how and where fraud is being perpetrated so they can better protect against it. The 2017 e-commerce fraud attack rate analysis shows: Delaware and Oregon continue to be the riskiest states for both billing and shipping fraud. Delaware; Oregon; Washington, D.C.; Florida; and Georgia are the top five riskiest states for billing fraud. Delaware, Oregon, Florida, New York and California are the top five riskiest states for shipping fraud, accounting for 50 percent of total fraud attacks. South El Monte, Calif., is the riskiest city overall, with an increase in shipping fraud of approximately 230 percent. Shipping fraud most often occurs near major airports and seaports due to reshippers and freight forwarders that receive domestic goods and often send them overseas. When a transaction originates from an international IP address, shipping fraud is 6.7 times likelier than the average, while billing fraud becomes 7.1 times likelier. Where is e-commerce fraud happening? Typically, the highest-risk areas for fraud are in ZIP™ codes and cities near large ports of entry or airports. These are ideal locations to reship fraudulent merchandise, enabling criminals to move stolen goods more effectively. Top 10 riskiest billing ZIP™ codes Top 10 riskiest shipping ZIP™ codes 97252 Portland, OR 97079 Beaverton, OR 33198 Miami, FL 33122 Miami, FL 33166 Miami, FL 91733 South El Monte, CA 33122 Miami, FL 97251 Portland, OR 77060 Houston, TX 97250 Portland, OR 33195 Miami, FL 33166 Miami, FL 97250 Portland, OR 97252 Portland, OR 97251 Portland, OR 33198 Miami, FL 33191 Miami, FL 33195 Miami, FL 97253 Portland, OR 33192 Miami, FL Source: Experian.com Source: Experian.com What’s more, many of the riskiest ZIP™ codes and cities experience a high volume of transactions originating from international IP addresses. In fact, the top 10 riskiest ZIP codes overall tend to experience fraudulent activity from numerous countries overseas, including China, Venezuela, Taiwan and Hong Kong, and Argentina. These fraudsters tend to implement complex fraud schemes that can cost businesses millions of dollars in fraud losses. Additionally, the analysis shows that traffic coming from a proxy server — which could originate from domestic and international IP addresses — is 74 times riskier than the average transaction. The problem The increase in e-commerce fraud attacks shouldn’t come as a huge surprise. The uptick in data breaches, merchants’ continued adoption of EMV-enabled terminals to protect against counterfeit card fraud and the abundance of consumer data on the dark web means that information is even more accessible to criminals. This enables them to open fraudulent accounts, take over legitimate accounts and submit fraudulent transactions. Another reason for the increase is automation. In the past, criminals needed a strong understanding of fraud methods and technology, but they can now bring down an entire organization by simply downloading a file and automating the submission of thousands of applications or transactions simultaneously. Since fraudsters need to make these transactions appear as normal as possible, they often leverage the cardholder’s actual billing details with slight differences, such as e-mail address or shipping location. Unfortunately, the mass availability of compromised data and the abundance of fraudsters makes it increasingly challenging to identify and separate legitimate customers from attackers across the country. Because of the widespread prevalence of fraud and data compromises, we don’t see billing fraud concentrated in just one region of the country. In fact, the top five states for billing fraud make up only about 18 percent of overall fraud attacks. Top 5 riskiest billing fraud states Top 5 riskiest shipping fraud states State Fraud attack rate State Fraud attack rate Delaware 93.4 Delaware 195.9 Oregon 86.1 Oregon 170.1 Washington, D.C. 46.5 Florida 45.1 Florida 39.2 New York 37.3 Georgia 31.5 California 32.6 Source: Experian.com Source: Experian.com Prevention and protection need to be the priority As businesses get a better understanding of how and where fraud is perpetrated, they can implement proactive strategies to detect and prevent attacks, as well as protect payment information. While no one single strategy can address the entire scope of fraud, there are advanced data sets and technology — such as device intelligence, behavioral and physical biometrics, document verification and entity resolution — that can help businesses make better fraud decisions. Fortunately, consumers can also play a major role in safeguarding their information. In addition to regularly checking their credit reports and bank/credit card statements for fraudulent activity, consumers can limit the data they share on social networking sites, where attackers often begin when perpetrating identity fraud. While we continue to help both organizations and consumers limit their exposure to e-commerce fraud, we anticipate that criminals will attempt more sophisticated fraud schemes. But businesses can stay ahead of the curve. This comes down to having a keen understanding of how fraud is being perpetrated, as well as leveraging data, technology and multiple layered strategies to better recognize legitimate customers and make more precise fraud decisions. View our e-commerce fraud heat map and download the top 100 riskiest ZIP codes in the United States. Experian is a nonexclusive full-service provider licensee of the United States Postal Service®. The following trademark is owned by the United States Postal Service®: ZIP. The price for Experian’s services is not established, controlled or approved by the United States Postal Service.

Optimizing your collections With a maximized approach to collections, you can see an uplift in performance of 5% to 30% in Key Performance Indicators against traditional techniques. Here are some suggestions for optimizing your strategies: Consider every combination of actions. Understand the tradeoffs between the different actions, which are forced by constraints. Choose the best set of actions to fit within the constraints. Maximize your collections efforts by knowing your customers better, segmenting and targeting your approach more effectively, and automating as much as possible. Learn more in our white paper Collections Optimization. Download now

Managing your customer accounts at the identity level is ambitious and necessary, but possible Identity-related fraud exposure and losses continue to grow. The underlying schemes have elevated in complexity. Because it’s more difficult to perpetrate “card present” fraud in the post–chip-and-signature rollout here in the United States, bad guys are more motivated and getting better at identity theft and synthetic identity attacks. Their organized nefarious response takes the form of alternate attack vectors and methodologies — which means you need to stamp out any detected exposure point in your fraud prevention strategies as soon as it’s detected. Experian’s recently published 2018 Global Fraud and Identity Report suggests two-thirds, or 7 out of every ten, consumers want to see visible security protocols when they transact. But an ever-growing percentage of them, fueled in no small part by those tech-savvy millennials, expect to be recognized with little or no friction. In fact, 42 percent of the surveyed consumers who stated they would do more transactions online if there weren’t so many security hurdles to overcome were — you guessed it — millennials. So how do you implement identity and account management procedures that are effective and, in some cases, even obvious while being passive enough to not add friction to the user experience? In other words, from the consumer’s perspective, “Let me know you know me and are protecting me but not making it too difficult for me when I want to access or manage my account.” Let’s get one thing out of the way first. This isn’t a one-time project or effort. It is, however, a commitment to the continued informing of your account management strategies with updated identity intelligence. You need to make better decisions on when to let a low-risk account transaction (monetary or nonmonetary) pass and when to double down a bit and step up authentication or risk assessment checks. I’d suggest this is most easily accomplished through a single, real-time access point to myriad services that should, at the very least, include: Identity verification and reverification checks for ongoing reaffirmation of your customer identity data quality and accuracy. Know Your Customer program requirements, anyone? Targeted identity risk scores and underlying attributes designed to isolate identity theft, first-party fraud and synthetic identity. Fraud risk comes in many flavors. So must your analytics. Device intelligence and risk assessment. A customer identity is no longer just their name, address, Social Security number and date of birth. It’s their phone number, email address and the various devices they use to access your services as well. Knowing how that combination of elements presents itself over time is critical. Layered passive or more active authentication options such as document verification, biometrics, behavioral metrics, knowledge-based verification and alternative data sources. Ongoing identity monitoring and proactive alerting and segmentation of customers whose identity risk has shifted to the point of required treatment. Orchestration, workflow and decisioning capabilities that allow your team to make sense of the many innovative options available in customer recognition and risk assessment — without a “throw the kitchen sink at this problem” approach that will undoubtedly be way too costly in dollars spent and good customers annoyed. Fraud attacks are dynamic. Your customers’ perceptions and expectations will continue to evolve. The markets you address and the services you provide will vary in risk and reward. An innovative marketplace of identity management services can overwhelm. Make sure your strategic identity management partner has good answers to all of this and enables you to future-proof your investments.

Identify your customers to spot fraud. It’s a simple concept, but it’s not so simple to do. In our 2018 Global Fraud and Identity Report, we found that consumers expect to be recognized and welcomed wherever and whenever they do business. Here are some other interesting findings regarding recognition and fraud: 66% of consumers surveyed appreciate seeing visible security when doing business online because it makes them feel protected. 75% of businesses want security measures that have little impact on consumers. More than half of businesses still rely on passwords as their top form of authentication. Even though you can’t see your customers face-to-face, the importance of being recognized can’t be overemphasized. How well are you recognizing your customers? Can you recognize your customers?
From malware and phishing to expansive distributed denial-of-service attacks, the sophistication, scale and impact of cyberattacks have evolved significantly in recent years. Mitigate risk by employing these best practices: Manage third-party risks. Regularly review response plans. Opt in to software updates. Educate, educate, educate. Organizations must adopt stronger, more advanced technical solutions to protect sensitive data. While enhanced technology is necessary for defending against data breaches, it can’t work independently. Learn more